
Embedding screenshots in Next.js Open Graph images
Introduction
This article expands upon a previous Open Graph image generation article: this time instead of dynamic text, we’re going to return a live screenshot of the page being shared as the Open Graph image itself - making the image act like a thumbnail. This will create far more eye-catching Open Graph images, which when shared in the wild should boost engagement. Picking up from where part one left off, we'll go from this:
To this:
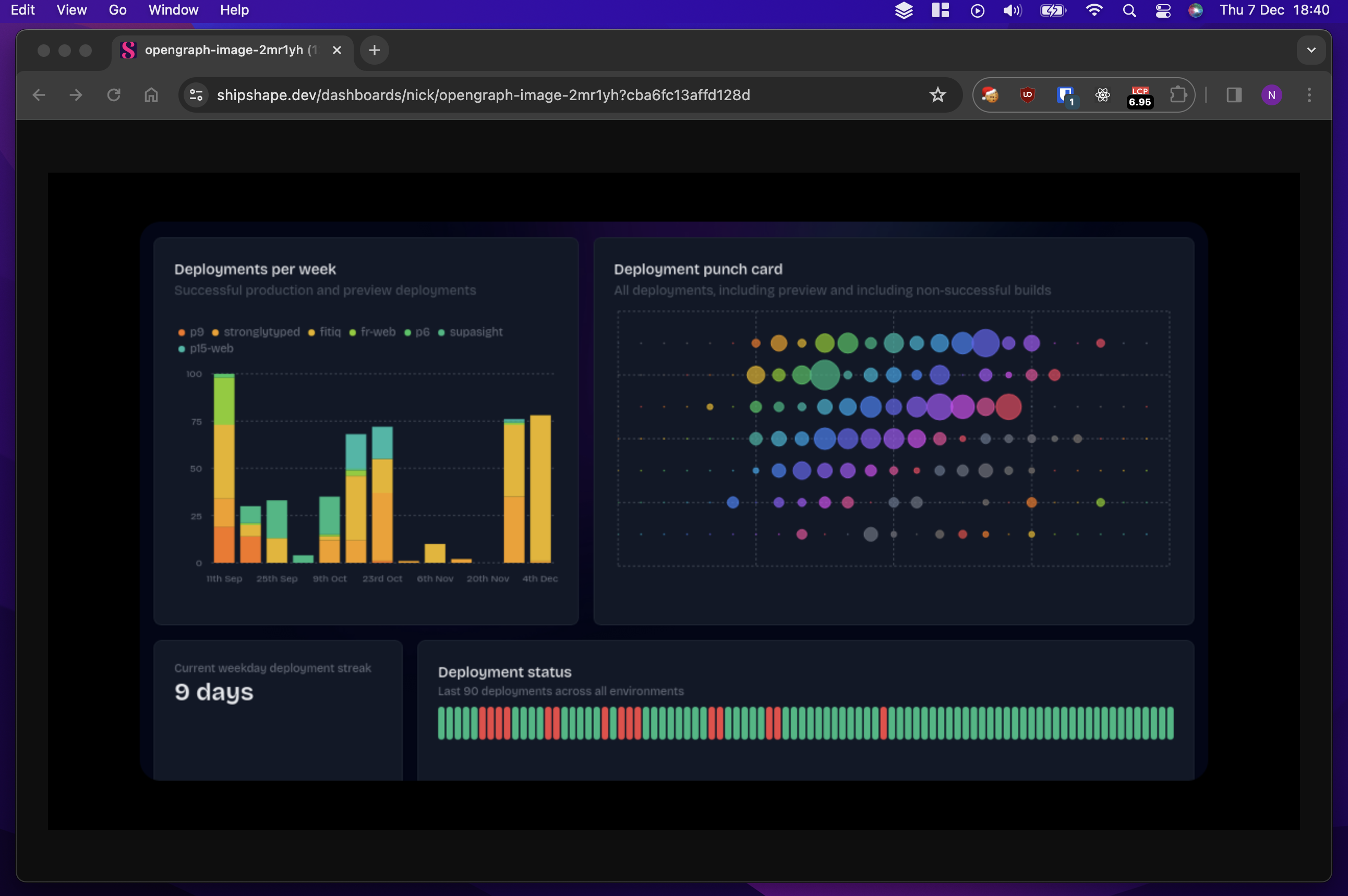
Which is really just a screenshot of this:
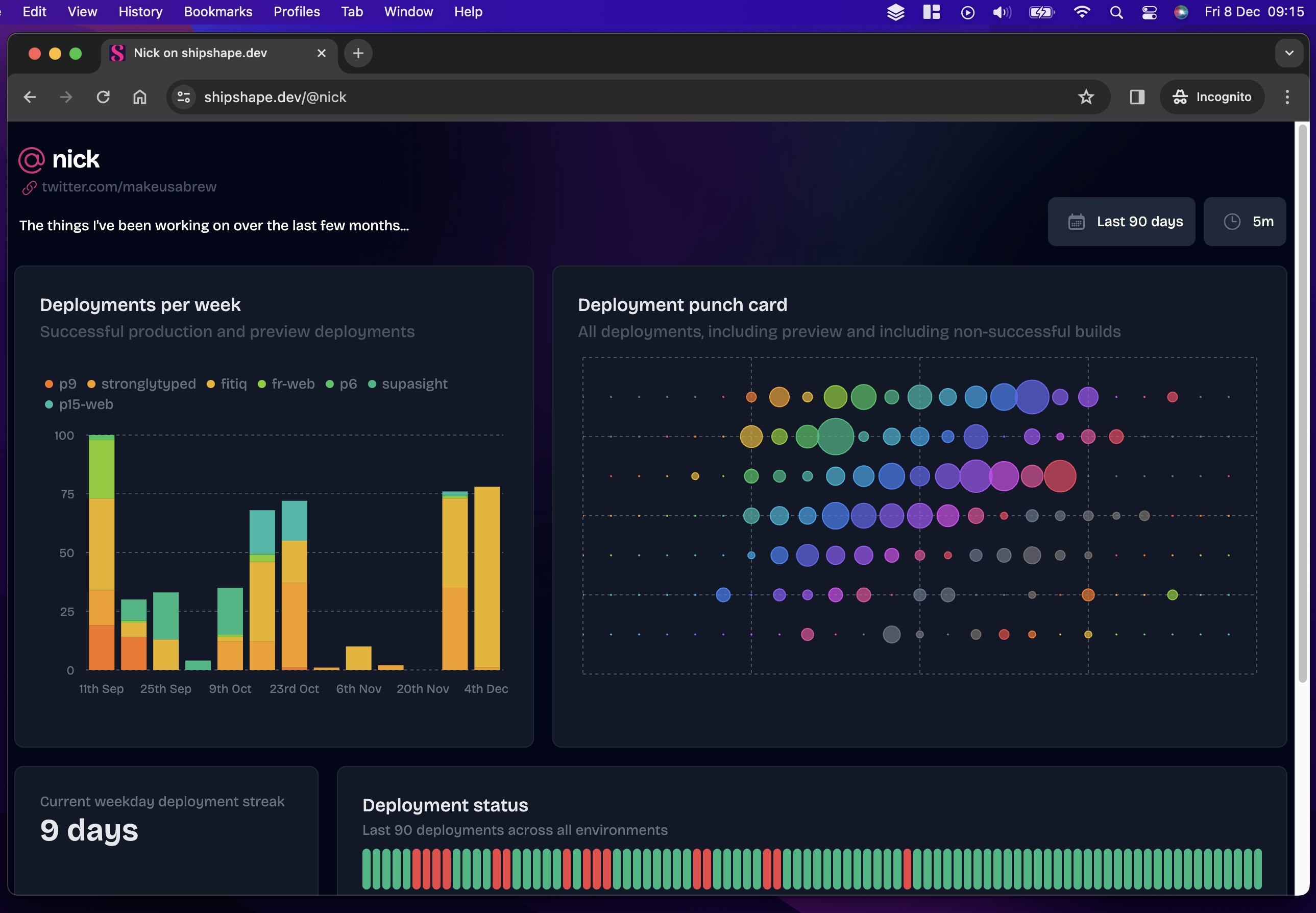
And when shared on social media, hopefully looks like this:
Wait, screenshots?
That’s right. Remember back to part one: the Satori rendering engine used under the hood of @vercel/og only supports a very limited subset of the HTML and CSS specs. If you're trying to create thumbnail-style Open Graph images of a website, you've got two main options:
- Go abstract: embrace the constraints of Satori and generate good-enough replicas of the pages you're trying to thumbnail
- Screenshot the target page in a real browser and embed that in your generated open graph image
You don't have to go down either route: it's perfectly possible to generate eye-catching images which don't look anything like the page being shared, but my use case was embedding real graphs with real-time data when people shared their shipshape.dev dashboards. The structure of these dashboards and their visualisations comfortably exceed Satori’s capabilities, leading to a straightforward choice to pursue option two.
At a glance request flow
Skipping ahead a bit, here’s a sequence diagram outlining the current shipshape.dev implementation, using Twitter / X as an example sharing platform:
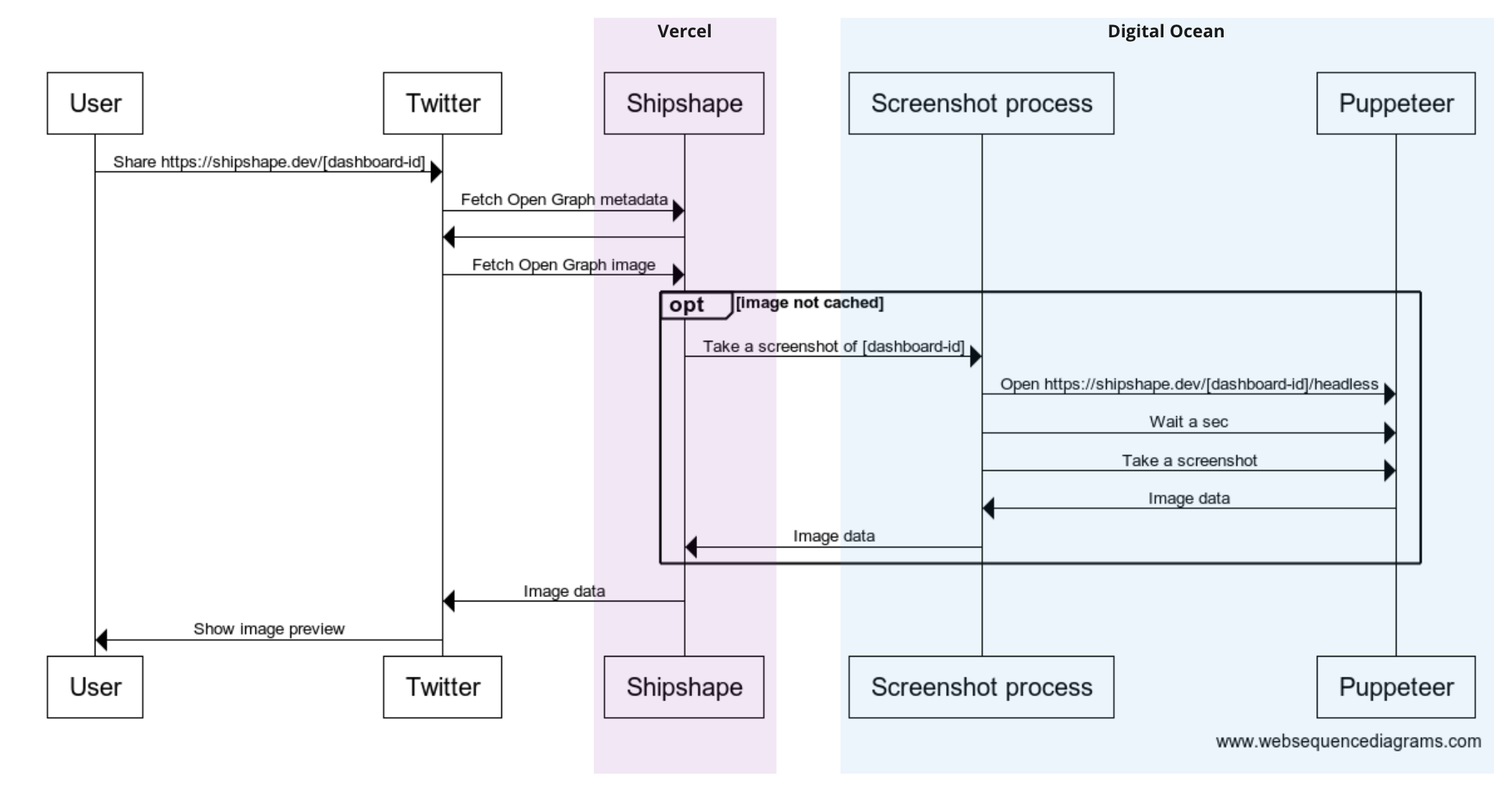
The implementation is straightforward but naive: lots of questions it doesn’t answer and edge cases not covered. As I'll explain later, this approach suffers from a variety of drawbacks to the point where I'm hesitant to recommend it. But it works, and it's a good starting point for further iteration. I'll briefly run through the main components, explain the rationale behind some decisions, and then examine those drawbacks in more detail.
Puppeteer
Puppeteer allows you to launch and control a headless chrome browser programmatically. That control can be as basic or complex as you like: if you can script it, Puppeteer can run it. The state of browser automation in 2023 is in rude health and depending on your use case Puppeteer is far from the only option: Selenium is still going strong, Playwright has the weight of Microsoft behind it and Cypress has unique features not found in the others, but in my case Puppeteer was the obvious choice. The requirement is simply to open a target URL, wait for the page to load, and take a screenshot. Here’s the ‘Screenshot process’ code in its entirety:
import pupeteer, { Browser } from "puppeteer"
import { createServer } from "http"
const delay = async (ms: number) => new Promise((res) => setTimeout(res, ms))
const screenshot = async (browser: Browser, slug: string) => {
const page = await browser.newPage()
await page.setViewport({ width: 1300, height: 680 })
const response = await page.goto(`https://shipshape.dev/@${slug}/headless`)
if (response && !response.ok()) {
console.log(`Failed to load ${url}: ${response.status()} ${response.statusText()}`)
return
}
const title = await page.title()
if (title === "404: This page could not be found.") {
console.log(`App router 404 page detected - bailing`)
return
}
// very crude way of waiting for graphs to animate
await delay(2500)
return await page.screenshot()
}
const run = async() => {
// Create a singleton browser instance
const browser = await pupeteer.launch({ headless: "new" })
// create a simple server listening out for screenshot requests
createServer(async function (req, res) {
const url = new URL(req.url || "", "http://localhost:9999")
const slug = url.searchParams.get("slug")
if (!slug) {
res.writeHead(400, { "Content-Type": "text/plain" })
res.write("Missing slug")
res.end()
return
}
const buffer = await screenshot(browser, slug)
if (!buffer) {
res.writeHead(404, { "Content-Type": "text/plain" })
res.write("Not found")
res.end()
return
}
res.writeHead(200, { "Content-Type": "image/png" })
res.write(buffer)
res.end()
}).listen(9999)
console.log(`Listening on http://localhost:9999, image target is ${targetHost}`)
}
run()
I run this script using pm2 on a Digital Ocean droplet: it boots a single chromium instance before starting a long-running server listening for incoming screenshot requests. You can think of it as an extremely minimalist ‘screenshot as a service’ service. It’s easy to imagine a more generalised and feature-rich version with an ergonomic stateless API which would allow others to use it too, but that sounds like a challenge for another day.
Digital Ocean
If you've read any of my other articles you'll know that I host everything on Vercel, but the Serverless paradigm has its limits - and my gut told me the screenshot process was beyond them. I didn't actually try and get Puppeteer running on Vercel, and there are certainly some workarounds to do so, but my main concerns were:
- Bloated bundle size: I'd need to package a chromium binary with my app, which would add a lot of unnecessary weight to the bundle
- Startup overhead: Loading and booting a chromium instance on every request would slow things down enormously
I already had a Digital Ocean droplet in service which I'd commissioned for launchloop, so there was little friction adding the screenshot process to it. One day I'd like to compare the performance characteristics compared to a Vercel implementation, but for now, Digital Ocean will do fine.
Headless dashboards
You might have already spotted that the Open Graph images generated by shipshape aren’t screenshots of the exact same dashboards users open in their browsers, and you might have already seen how. Here’s a direct comparison, dashboard page first:
And its corresponding Open Graph image:
I pondered a few different ways to chop off the header before settling on the path of least resistance: serve a ‘headless’ version of each dashboard under a different URL. The code on the shipshape side of things to fulfil this is trivial and is essentially a duplicate of the dashboard page minus the header components. Clearly, our maybe-one-day screenshot as a service service would need to have to solve this problem more generally, but for my needs, it was just fine. Below is a screenshot of this headless dashboard - it is: exactly this URL which the screenshot process takes a snapshot of:
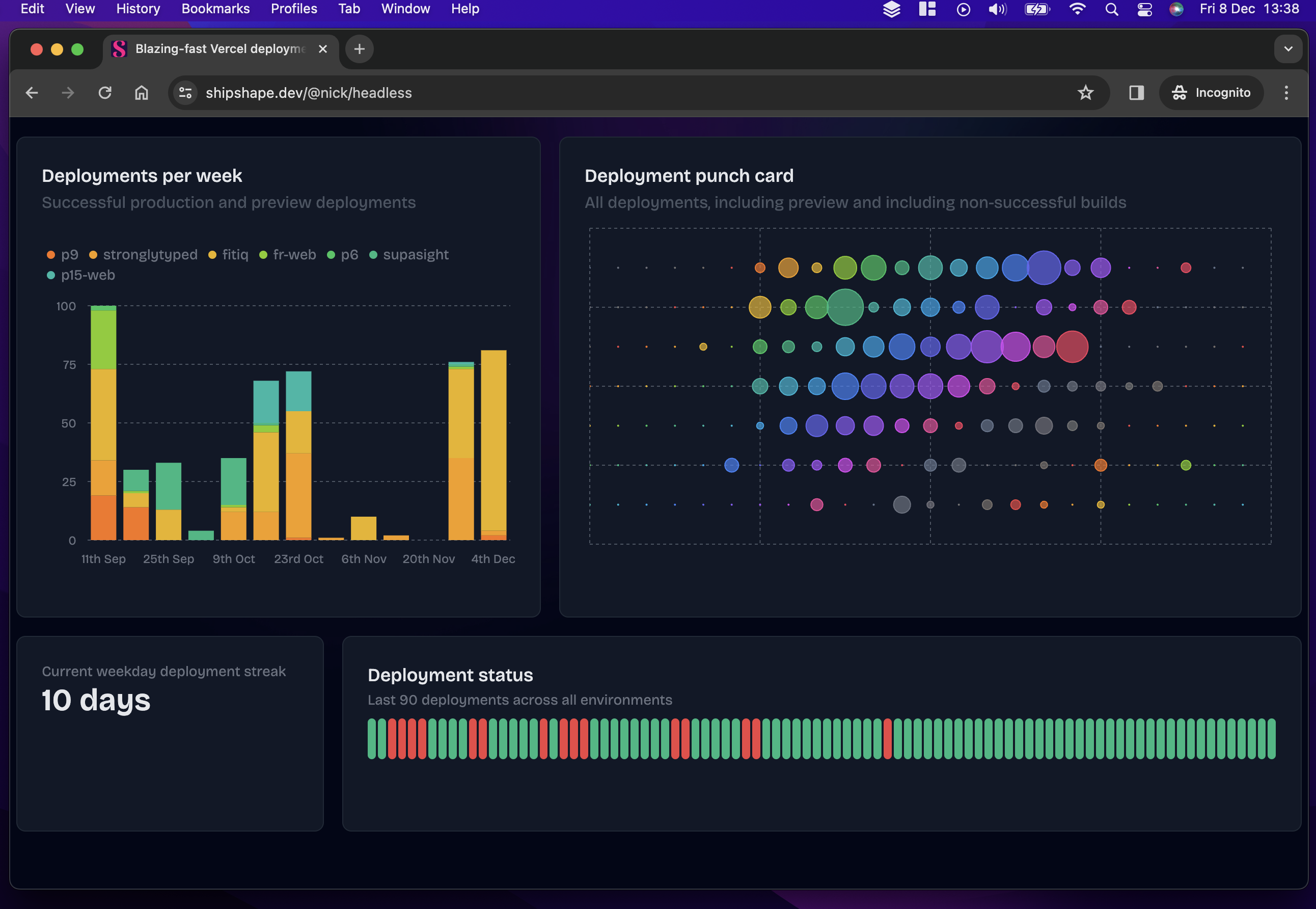
It’s worth noting that there’s nothing secret about the headless URL: users are welcome to view it in their browser if they want, and it doubles up as a good way to view dashboards on big screen TVs too.
The Open Graph image handler
All that's left to discuss is the code which fetches the screenshot and generates the Open Graph image in the first place. If you look really closely at the image above, you'll notice that the screenshot is actually framed by a black border and has a subtle rounding effect to it. That's controlled by the JSX provided to Satori when rendering the image. Let's take a look:
import { dashboardExists } from "@/lib/admin/dashboards"
import { ImageResponse } from "next/server"
export const runtime = "edge"
export const alt = "Open graph image"
export const size = {
width: 1200,
height: 630,
}
export const contentType = 'image/png'
export default async function Image({ params }: { params: { id: string } }) {
if (!dashboardExists(params.id)) {
// much quicker to short circuit if we *know* the ID doesn't exist...
return new Response("Not found", { status: 404 })
}
const url = `${process.env.OG_IMAGE_HOST}?slug=${params.id}`
const imageRes = await fetch(url, { next: { revalidate: 300 } })
if (!imageRes.ok) {
console.log(`Error fetching OG image: ${imageRes.status} ${imageRes.statusText}`)
return new Response("Not found", { status: 404 })
}
const buffer = await imageRes.arrayBuffer()
console.log(`Returning OG image for ${params.id}`)
return new ImageResponse(
(
<div
style={{
display: "flex",
width: "100%",
height: "100%",
flexDirection: "column",
justifyContent: "center",
alignItems: "center",
background: "black",
}}
>
<img src={buffer} width="1024" style={{ borderRadius: 20}} />
</div>
),
{
...size,
}
)
}
A lot of this code will look familiar if you followed along with part one.
The only major difference is that the resulting JSX contains an <img> tag rather than plain text.
Implementation drawbacks
I've already hinted at some of the drawbacks of this approach, but there are quite a few of them which are worth being honest about.
It requires additional infrastructure
This is the most obvious drawback: running a separate server managing the screenshot process. Maybe you've got a spare VM or two hanging around, or maybe you're repared to work around your Serverless provider's limitations, but in my case, it is undoubtedly an extra complexity I'd rather do without.
It’s slow
You'll notice I've got a rather sheepish await delay(2500) in the screenshot process code. This
is mainly because the graphs on shipshape transition in after page load.
Most of the time 2.5 seconds is way too long, and very occasionally it's not long enough: a better
solution would be to use Page.waitForSelector and
to remove graph animations when serving headless dashboards. I need to get around to both.
It’s unreliable
If you just try and load a shipshape Open Graph image in your browser, it will load reliably. But when you're sharing a link on a social network, that social network is in charge of fetching the image and deciding on appropriate timeouts when doing so. This means sometimes an uncached image doesn't load in time and gets omitted from the link a user is sharing. Bummer.
It’s inefficient
I talked earlier about wanting ‘real-time’ data in the dashboards snapped by the screenshot process, which - along with its architectural simplicity - is the reason for the ‘pull’ model of fetching screenshots on demand.
But why? Who really cares if they share a link to their dashboard on social media and the image isn’t entirely up-to-date? The answer of course is: nobody. Except me. It’s a naive implementation which won’t scale and has more downsides than up. In truth it needs revisiting soon: better to have a pre-generated but fast image ready to serve than a second-accurate one which starts going stale the moment it’s shared anyway. Besides, there’s another huge gotcha to contend with which blows this requirement out of the water anyway:
Social networks aggressively cache Open Graph images
If someone shares a link on a social media platform which someone else has shared before, the chances are the associated Open Graph metadata is already cached on that platform's servers and will not be refetched, regardless of what your carefully crafted cache-control headers say on the matter. Sure, some of the usual cache-busting tricks might work - like appending a random query string parameter to the URL being shared - but good luck asking your users to do that (please don't ask your users to do that).
Recommendations
With that litany of errors out of the way, I’d like to focus on some constructive takeaways instead.
Design your Open Graph images to be cacheable
Dynamically generating Open Graph images is fine, but I wouldn’t recommend changing a generated image all that often, if ever. Certainly, my ‘real-time’ data requirement wasn't just unnecessary, it was hopelessly naive. Remember that you’re not in control of the process which actually requests these images and other Open Graph metadata, and neither are your users: the platforms you’re sharing it on are. They decide when to fetch your image and what to do with it. In the worst case you can politely ask a user to clear their cache or force reload a page, but you can’t ask Facebook (edit: apparently you can, but good luck integrating that into your workflow!).
Serve image responses quickly
I don’t have hard numbers to give you here, just anecdotal evidence: links I was sharing on various platforms which required a full round trip to generate a new screenshot often didn’t show the image at the first time of asking. WhatsApp was easier to convince a few moments later once I was sure a screenshot had been generated and cached, but other services like X were far more stubborn. I’m speculating when I say so but my suspicion is X was happily caching a lack of image data alongside valid title and description elements of the same page, meaning subsequent shares of the same URL didn’t attempt to re-fetch it.
Stick to the recommended Open Graph image dimensions
This isn’t specific to embedding screenshots or images inside your Open Graph images but it’s worth stating: always generate images at 1200x630 - the de facto standard image size, otherwise some platforms like WhatsApp will ignore your image completely. If you’re embedding screenshots like I am, your source image can be different dimensions, but don’t be tempted to use those for your actual Open Graph image. If you look through the code snippets in this article you'll notice that neither the dimensions I'm using in Puppeteer or when embedding the resulting screenshot match these dimensions, but the crucial thing is that the returned image does.
Focus on engaging images, not technical indulgence
Open Graph images should be about improving engagement, but I got too fixated on my quest for pinpoint data precision without considering the user experience or platform requirements. Almost everything in Software Engineering is a trade-off, and in this case being prepared to sacrifice screenshot freshness for a faster and more robust sharing experience should have been a no-brainer.
Possible improvements
As you approach the end of this article you might be confused as to where to go next. Do you follow this approach in spite of its drawbacks, or do you take a different approach? I think you've got a few options:
Optimise the current approach
I run the screenshot process on a single-core 2 GHz VM with 2Gb RAM. A whole load of
raw performance awaits by simply speccing up the VM running this process. Combined with
eliminating the need for an arbitrary delay() before taking the screenshot, this
might make the existing approach good enough for most situations
Use a third-party screenshot service
Developers are renowned for reinventing the wheel under the false assumption that they can do so (a) better, (b) cheaper or (c) both, and then they go and build flakey screenshot processes like I've done here. You might want to look at a third-party service like ScreenshotOne and save yourself the headache and blushes instead.
Switch to a different model
I'm in full control of the data flow through shipshape, so it'd be perfectly possible to "push" a screenshot request when a dashboard actually needs updating. Some care would be needed to throttle and debounce requests, but the approach is viable. Combined with generating an initial image for a dashboard upon creation would mean always having an image ready to serve. Depending on your appetite for a large bill at the end of the month, you could get the throttling / debouncing tolerances down pretty low in favour of keeping images as fresh as possible. Like I said: it's all about trade-offs.
When I next sit down in earnest to tackle the shipshape backlog, this is probably the approach I'll take. Who knows, maybe one day there'll be a part three to this series!
Conclusion
For not a lot of code and a little bit of infrastructure, you can embed thumbnail-style screenshots in your Next.js-generated Open Graph images. Just remember: the platform your users share your links on is in charge of fetching and caching your Open Graph metadata, and they're likely to do so aggressively (you probably would too if you had three billion monthly active users). Optimise your screenshotting process for speed and optimise your Open Graph images for engagement instead of accuracy, and you'll be just fine.