
Bluesky firehose, meet Hacker News
Introduction
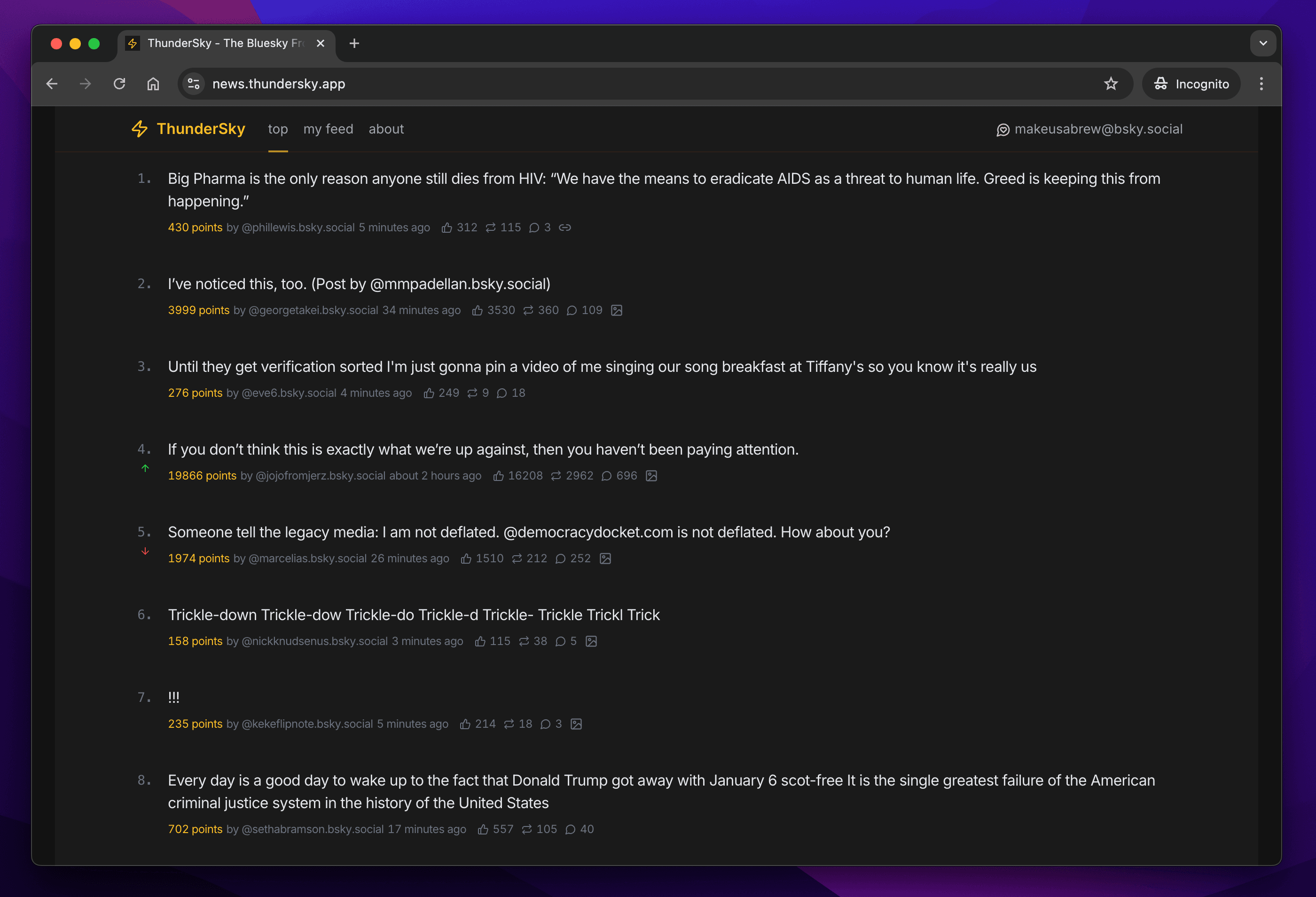
I shipped ThunderSky yesterday after hacking on it over the course of a few evenings this week. The concept is simple: consume the Bluesky firehose and rank posts according to a Hacker News-inspired algorithm, serving up a Bluesky "front page" driven by post engagement with a strong bias towards post recency. I was expecting enormous differences in volume, content and selectivity between the hand-picked submissions of Hacker News vs the deluge of posts on Bluesky, but it seemed like an interesting problem space and one I hadn't tackled before.
Background
I love fast-changing, high-volume data, but I don't often get to work with it. Many years ago, back when Twitter provided a Streaming API for the great unwashed, I built a thing called nodeflakes—real-time, tweet-powered snowflakes drifting down a web page of your choosing, turned on once a year in the run up to Christmas. That was a lot of fun, until Twitter’s Christmas spirit deserted them (not to mention when they sold it to Elon, who now wants to charge you $60,000 a year for the pleasure of accessing a filtered version of the stream).
Bluesky is a not-new-but-newly-popular microblogging platform, whose ethos and openness echo that of early Twitter. It has a fully supported firehose which lets you stream everything going on in the network. They also provide an open-source relay server called Jetstream which provides a simpler API for the majority of use cases which don't require the raw firehose. As if that wasn't enough, they even operate four official Jetstream servers, which anyone can connect to using a WebSocket connection, without authentication, and receive JSON-encoded events from the firehose at full speed. That's pretty amazing. I was itching to play with it, and so the idea for ThunderSky was born. Now I needed to learn more about how Hacker News worked.
Ranking algorithm
Simplified, the Hacker News algorithm is (or was) Score = (P-1) / (T+2)^G, where:
- P is the number of points the post has accumulated (the -1 is because the submission upvote doesn't count)
- T is the age of the post in hours (the +2 prevents brand-new posts getting too much of a boost)
- G is a gravity constant (reportedly set at 1.8)
T and G are easy enough to port across, but what about P? We don't have people selectively choosing which posts
to submit to ThunderSky, nor do we have eyeballs on the site ready to vote on them. Where we do have eyeballs
is on Bluesky, so I elected to derive points from engagement: Points = Likes + Reposts + Replies.
I played around with assigning different weights to different types of engagement, but I'm yet to find a good variation which doesn't feel completely arbitrary. Since points are displayed prominently alongside each post, I want the calculation to be obvious (especially as likes, posts and reposts are shown alongside them) rather than smell like algorithmic smoke and mirrors.
The follower factor
All new posts on Hacker News are treated equally and are put before the same pool of watching eyes (if you ignore the flywheel effect of making it onto the front page), whereas the audience for a given Bluesky post is driven largely by the author's follower count, creating a towering bias towards bigger accounts. Early versions of ThunderSky didn't account for this and found that not only did the biggest accounts dominate the front page but they could actually almost "out run" the time decay effect; they just kept snowballing likes and reposts and staying ahead of the curve for hours on end. After a bit of back-and-forth with ChatGPT and a lot of subsequent tweaking, ThunderSky now accounts for the follower factor to try and minimise the inherent advantage of large accounts with massive reach. The odd whale account still breaks everything every so often, and the algorithm could do a lot more to "boost" smaller accounts. Work in progress.
Follower numbers aren't part of each post's event payload, which means they need to be fetched on demand by calling the Bluesky HTTP API. This has an interesting knock-on effect elsewhere in the ingestion and ranking process, as we'll see later.
Backend design
There are some interesting design decisions to be made when building a system like this, of which the algorithm discussed above is one. But when should it run? Do all posts get pointed and ranked? How and when do we trigger time-based decay on all active posts? What data structures should we use to quickly and efficiently rank posts and update the front page? What happens when the data you need to make a decision isn't immediately available and requires a slow network call?
These questions become even more interesting when you consider the volume of "submissions" ThunderSky processes, amplified by the frequency of "upvotes" they receive: thousands of combined events per second make for a constantly changing data set.
Event processing
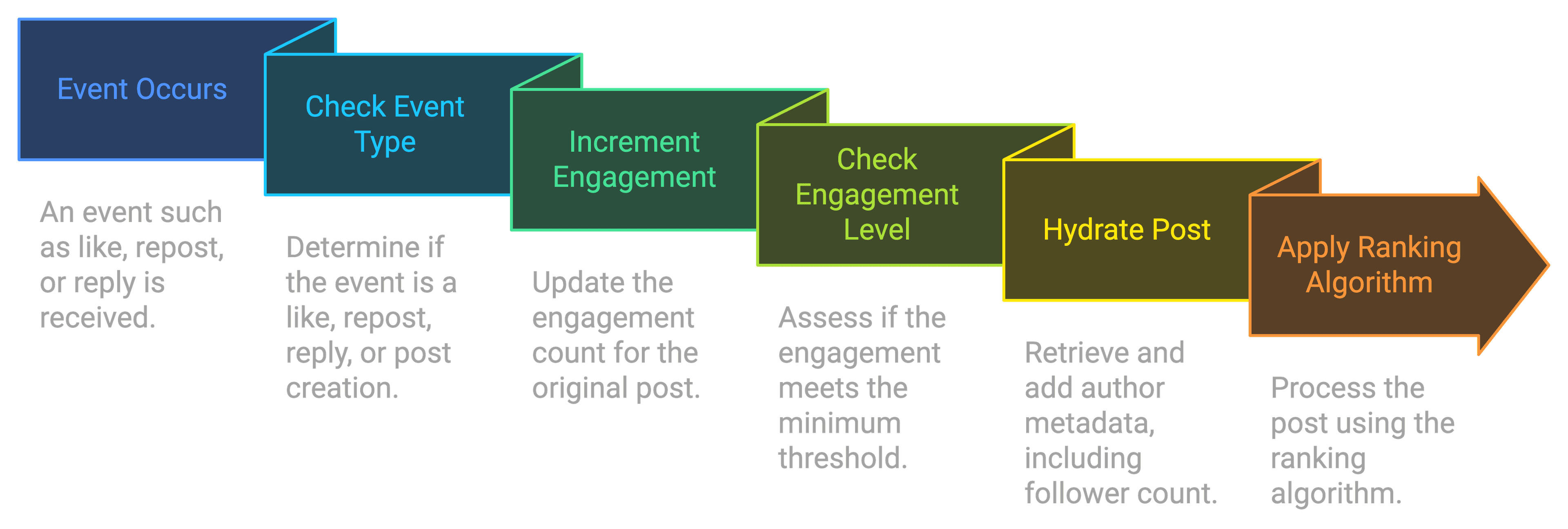
I've already discussed the fact that follower counts aren't included in the post (or like, repost or reply) event payload and need to be retrieved from the Bluesky HTTP API. We can't rank posts without follower counts, but we can't realistically hit the API for every new post we ingest: it would slow things down considerably, we'd get rate limited, and we don't actually need to fully rank posts until they've received at least some engagement. The ingestion pipeline reflects this trade-off:
- If the event is a like, repost or reply, look up the original post and increment the appropriate property's value
- If
sum(like + repost + reply) >= MIN_ENGAGEMENT, hydrate the post with author metadata (including follower count) - Apply the ranking algorithm to the post if it has been hydrated
If the event is a post creation, we simply store some skeleton data with zeroed-out scores and wait for engagement. This design decision means ending up with a lot of posts with no engagement, taking up a lot of memory, but it's a deliberate decision with two main upsides (and posts with no engagement at all after 30 minutes are deleted):
- No need to look up the post's details via the HTTP API when processing engagement for a previously unknown post
- No need to sync (and possibly correct) the post's engagement values with the actual values from Bluesky, since we've tracked its engagement since post creation
I started off with the opposite approach of lazily backfilling posts on demand, but ended up with a system whose state was much harder to reason about and by its very nature was prone to inconsistency.
State
State is kept in three main maps in memory, all keyed by post URI:
- Basic posts: posts which haven't yet crossed the minimum engagement threshold to trigger a follower count fetch, but whose likes, replies and reposts we're tracking
- Enriched posts: posts which have crossed the threshold and for which we have retrieved the follower count
- Scored posts: display scores (points) and ranking scores (factoring in post age and follower count) for each post
There's no duplicated data between any of the maps: if you want the full view of a post along with its score, you're fetching it from all three maps. Now I reflect on it, there's no need for that third map—it's a remnant from an experiment during development where posts could be inserted into multiple categories and thus were selectively ranked for some feeds but not others.
In order to restore in-memory state on restart, there's also a quick and dirty process which dumps the maps to disk when
the process receives SIGINT or SIGTERM (don't ask what happens if it crashes, okay?). This, along
with the cursor position of the last received WebSocket event, is read back on startup to restore state and resume where
things left off.
Time decay
Absent any engagement, time decay still needs to be applied to all active posts. I didn't spend much time worrying about this: once a minute all qualifying posts are iterated and reranked.
Leaderboard
The backend ingestion process sorts and serialises the top 25 posts to JSON and writes the result to a Cloudflare R2 bucket every
30 seconds. This bucket is configured to be publicly readable with access control headers explicitly allowing two origins: localhost
and news.thundersky.app. Note that I said sorts as well as serialises: from the previous section you'll have seen
that ranked posts are stored unordered and only sorted into position on demand. I've chosen to optimise for write
performance during ingestion and only pay the cost of sorting by rank when needed. This simple approach probably
won't scale past a certain point, but it works for now.
Frontend design
I didn't design any of the ThunderSky frontend by hand. I gave Cursor composer some ideas to work with, and iterated on the design intermittently over the course of a few days. Occasionally I'd play Cursor off against v0, asking one to improve the other's design and cherry-picking the best bits from both. This is a pattern I've used before and I'm a big fan of it. I made the more surgical tweaks myself in places where using Cursor would be an unweildy hammer to crack a tiny nut, but that's about it.
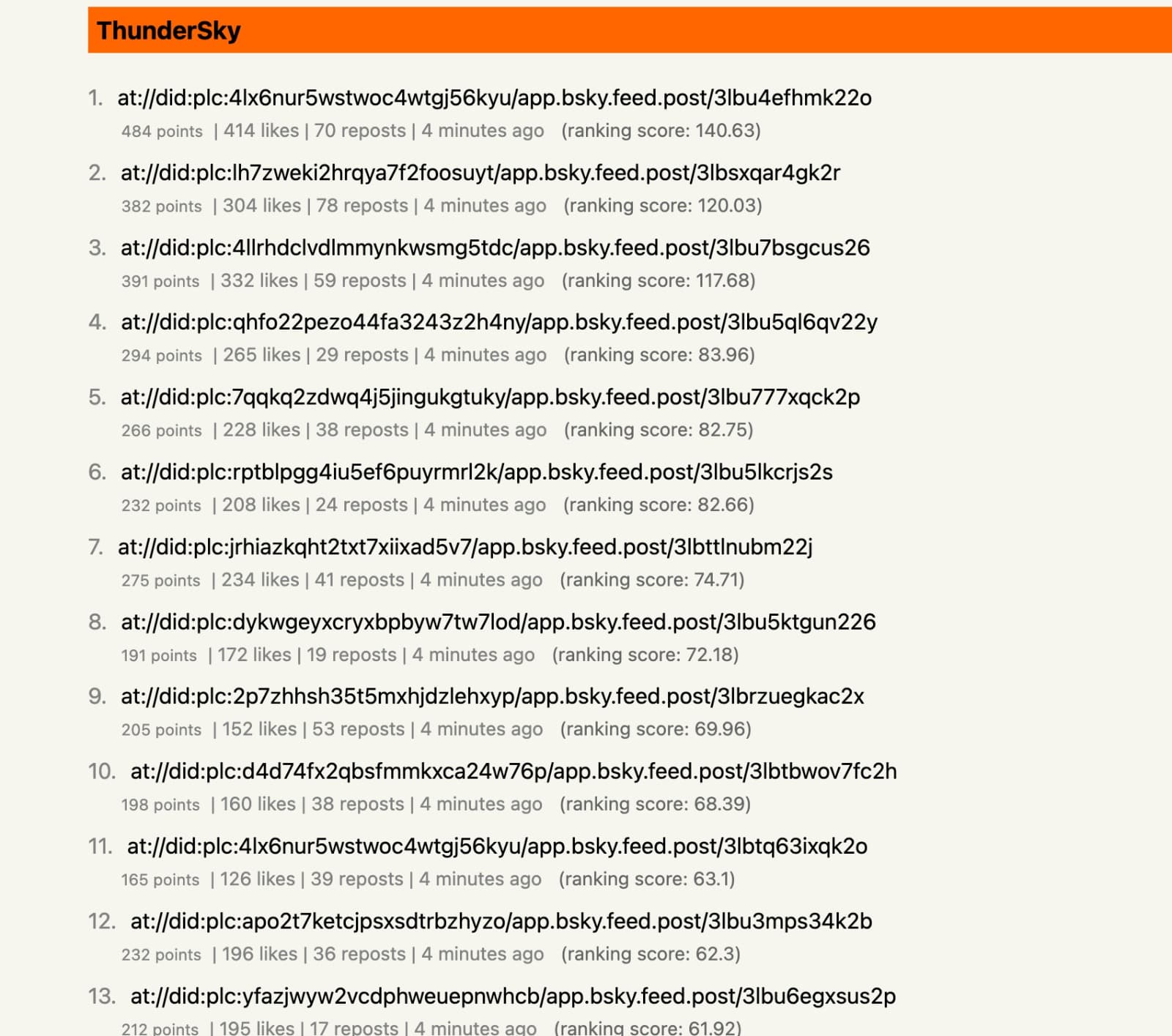
Just for fun, here are some screenshots of the very earliest prototypes (with no prizes for guessing where Cursor drew its inspiration for that first design). The first screenshot only renders post URIs because at this point I was processing engagement events (which only have a reference to the post's URI, not its details) as discussed in the previous section on event processing:
In a later version I asked for a more stormy palette and got... this. Posts are either being hydrated via an API call here, or I've switched to ingesting posts before tracking engagement. In either case, author details are definitely being fetched from the Bluesky API:
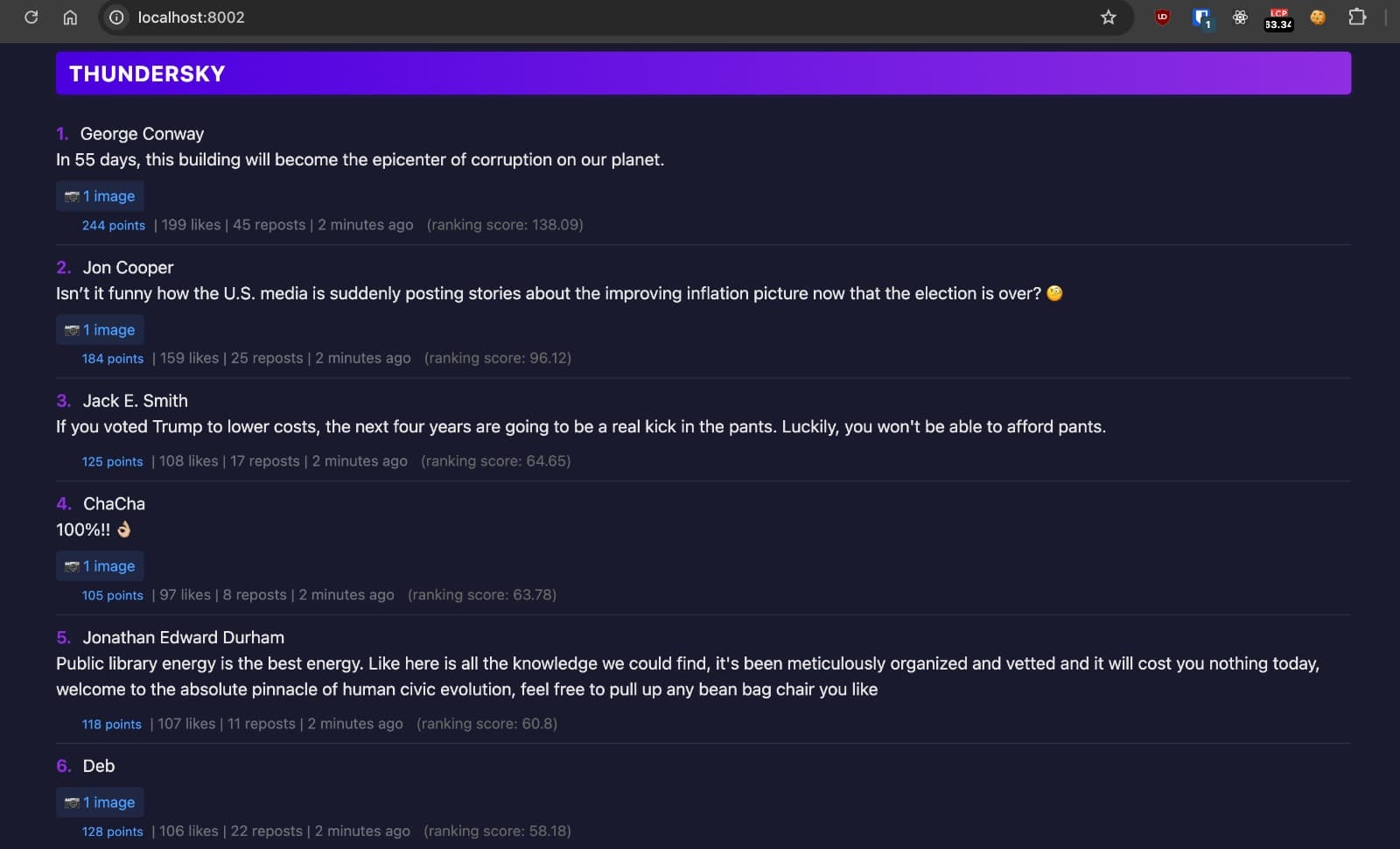
Below you can see the final colour starting to take shape, and I'm experimenting with a thumbnail showing the either post's embedded image or the author's avatar if the post doesn't have one. A few eyefuls of unexpected NSFW content later, I got rid of this:
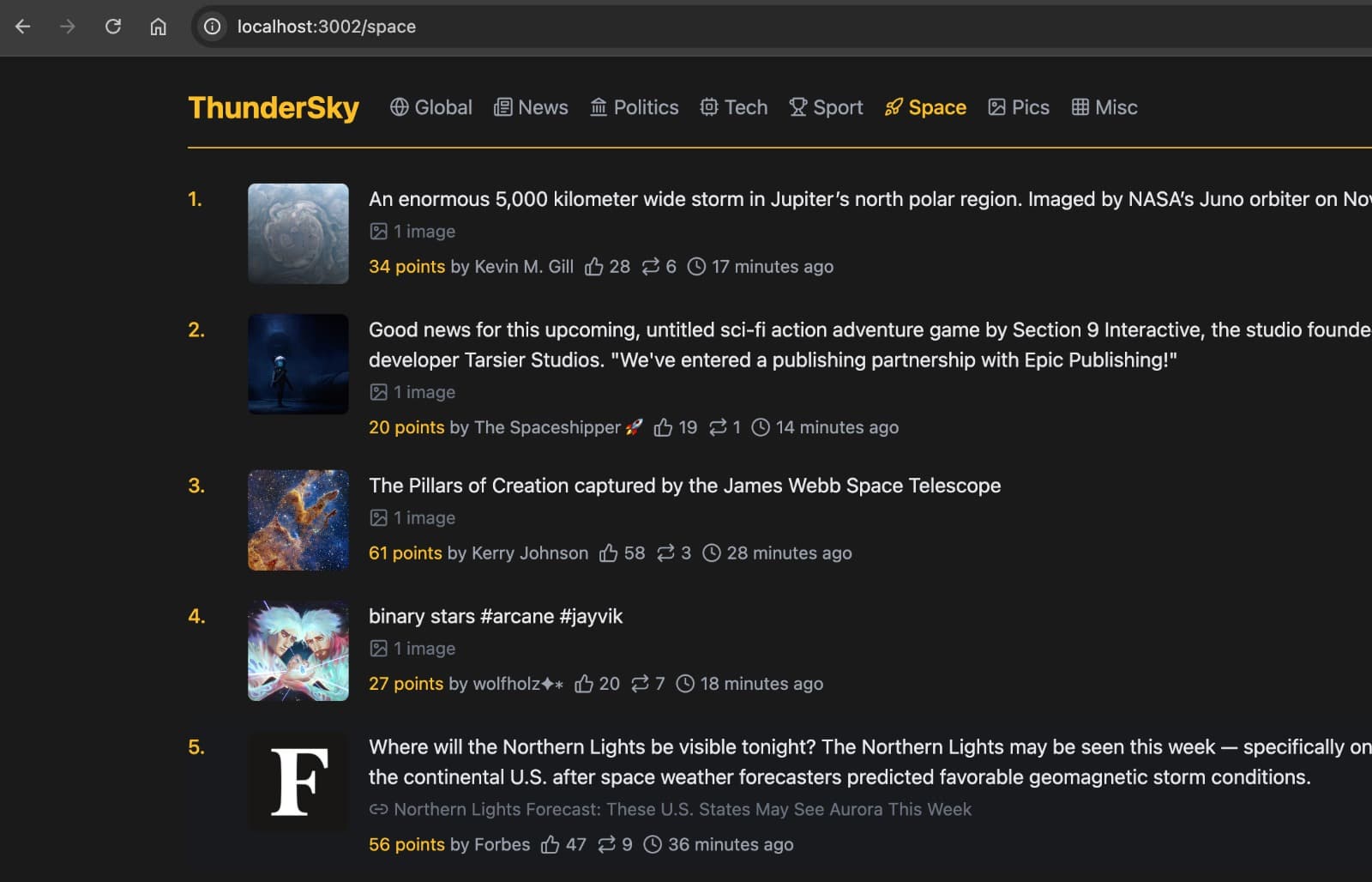
And just in case you've forgotten what the final design looks like, here it is again:
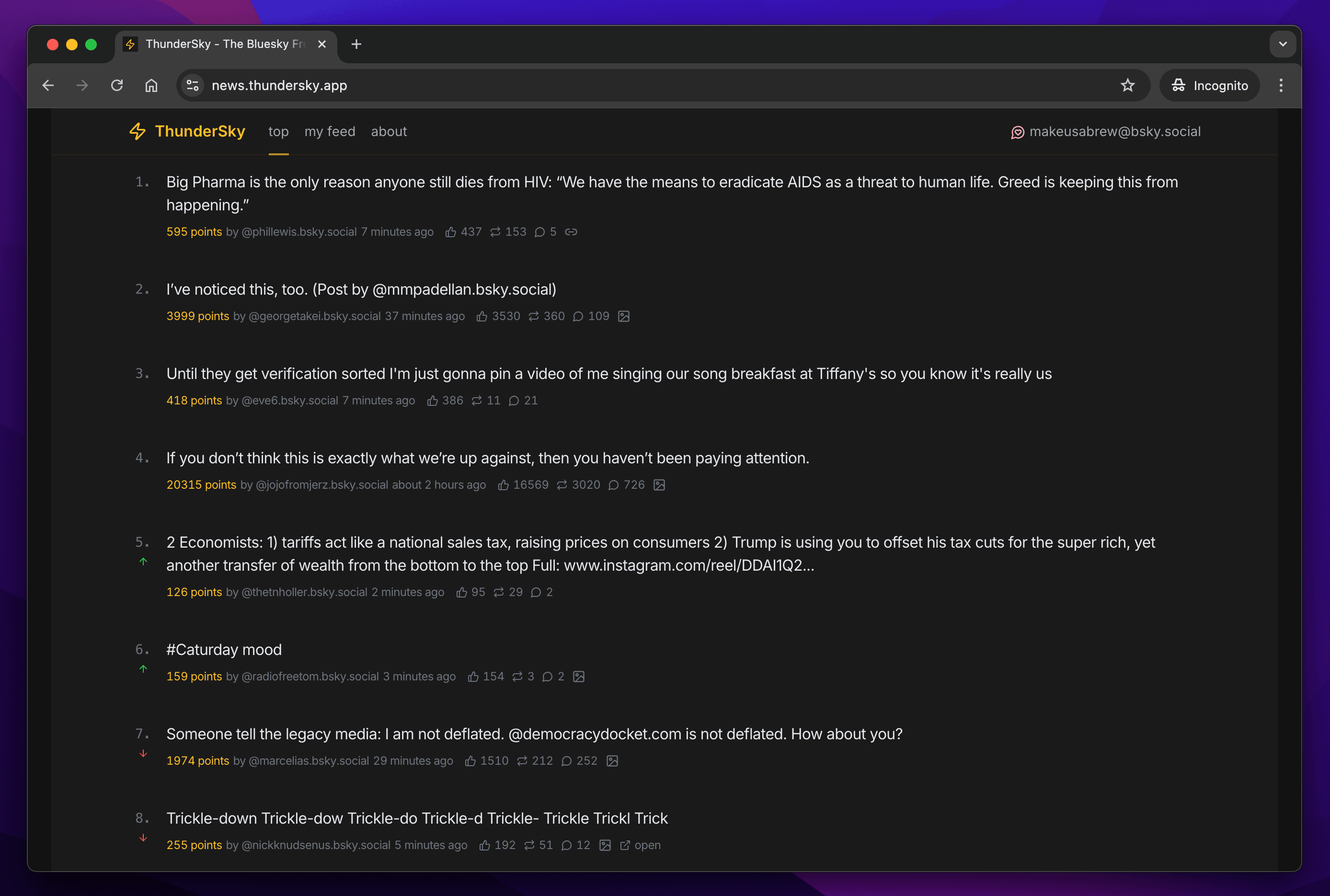
My favourite design aspect by far are the green and red arrows indicating which way a post is moving up or down the rankings (look at positions 5 to 8 in the above screenshot). Along with motion animating the movement of posts when they change rank, this helps enormously with understanding what's happening. The frontend auto-refreshes every few seconds, and without these touches I found the experience jarring, with content seemingly randomly jumping around the page.
Tech stack
Backend
The ingestion and ranking process is written in TypeScript, executed using the Bun runtime. I chose Bun for a few reasons:
- I wanted to try it out.
- It's demonstrably fast.
- TypeScript is my current go-to language when I want to ship quickly, and natively being able to run it is a big win.
- I knew from the offset that there would be a lot of data to manage, and hoped Bun's performance could paper over the cracks of my shoddy data structures and algorithms.
So far Bun has been rock solid; everything just works, and I'm very impressed. I'd like to benchmark my use case against Node.js and maybe Deno 2.0 sometime.
I built ThunderSky in a handful of hours over a few days, so don't be appalled when I tell you that the ingestion process currently runs on my MacBook Air. The project is just a bit of fun after all, and running locally means I save a substantial amount of money vs the equivalent specced VM running somewhere in the cloud. In the worst case if the process stops or I let the MacBook go to sleep, the only impact is stale rankings on the site.
Frontend
The usual suspects for me here: Next.js, Tailwind CSS, hosted on Vercel. The website today is all static content, so
could really be built in anything and hosted anywhere, but I had no reason not to use my familiar toolkit. For a while
the early protoypes used a static index.html page with inlined CSS and JavaScript, which I thought was very
HN-esque in its minimalism, but soon became a bit cumbersome for my liking.
Tooling
If you're a developer and AI isn't yet a part of your toolchain, you are missing out on a huge amount of enrichment and a massive uplift in productivity. Not leaning heavily on AI is like deliberately choosing not to bring a calculator into a maths exam 30 years ago. As already mentioned under 'Frontend design', I use:
- Cursor composer to implement and iterate on my ideas, and build my frontends
- v0 for design inspiration when Cursor needs a hand
- ChatGPT for more long form ideation, which I then feed into Cursor or v0
Cursor is perfectly capable of ideating since it's Claude 3.5 sonnet under the hood, but I just prefer the ergonomics of the ChatGPT interface for long form conversations, and don't have to worry about it being overly code-focused if I don't want it to be.
Hosting
I've mentioned both separately already, but the frontend website is a NextJS App Router app hosted on Vercel, which periodically polls a Cloudflare R2 bucket for the latest rankings. The website is currently completely static, so could be hosted absolutely anywhere, but I use Vercel everywhere else so there was no reason not to do so again.
Drawbacks
Content
The most obvious are the types of content which regularly dominate the front page:
- Political
- US centric
- So-called "hot takes"
- Occasionally NSFW
The first two are to be expected given the current mass migration of left-leaning US-based X users to Bluesky in light of the recent US election results and Musk's increasing association with the incoming Trump government. The third is probably the nature of the attention-grabbing nature of microblogging platforms. And the fourth is just, well, the internet.
Personally, it's not even so much that I want ThunderSky to be tech-oriented like Hacker News from which it draws its inspiration, it's that I actively don't want it to be dominated by US politics (but to each their own, of course).
Post turnover
The second big drawback is post turnover/churn. With a huge "submission" rate, I have yet to find the right balance between giving new content exposure vs. not constantly reshuffling the front page and making the user experience too disorientating.
Duplicated content
The third big issue at present is duplicated content. I've seen this range from exact duplicated content amplified across different accounts, to near-identical content, to the same subject articulated in different ways. This gets irritating pretty quickly, but I think the fix is actually pretty simple: given that only a small subset of posts ever make the front page (and ThunderSky doesn't let you even see the rest), it should be possible to cache the most popular post content in a sliding time window and penalise new posts based on similarity and recency. Levenshtein distance would help catch exact-match or near-match duplicates, and selective use of AI could probably mitigate the rest. There's definitely some low-hanging fruit to go at here.
Lack of user impact
ThunderSky users can't materially influence the shape of the front page. They are free to interact with posts on Bluesky, but if a post already has 45,000 likes, your "vote" isn't going to make any difference. There is a total disjoint between the users "voting" for posts and the audience reading them on Bluesky (which is mostly just me).
Future improvements
Categorisation
One version of ThunderSky briefly called out to gpt4o-mini during the hydration pipeline, attempting to classify posts based on their content, or failing that, their author's profile. The categories were:
- News
- Politics
- Technology
- Sports
- Space (biased much, Nick?)
- Other
The categorisation sort of worked, but it didn't add much value and came at the cost of ranking latency and expense calling the OpenAI API. Given that the ranking process currently runs locally on my Mac (which is, I hope, a temporary state of affairs), I'm toying with the idea of running a local LLM like llama-3.211b, but even so, the latency will still exist, and even if the categorisation was absolutely perfect the categories are still fixed, small in number, and biased towards my own interests.
Personalisation
The next logical step beyond categorisation is personalisation. Many years ago Harry Roberts and I built a thing called faavorite, which re-imagined your Twitter feed as tweets that the people you followed were favoriting (as likes were called, at the time). This kind of meta feed worked really well, surfacing up lots of interesting content back in the days before "the algorithm", and if it weren't for my terrible code causing it to grind to a halt once it started gaining traction, coupled with cloud costs at the time being much higher than they are now, you might have even heard of it.
I think the same idea could be applied to ThunderSky, serving up a front page of posts that the people you follow are engaging with. The biggest challenges I can foresee are:
- Content freshness. Depending on how many people you follow and what they're doing, you might end up with the opposite problem of the current front page and end up with a lot of stale content.
- Data storage: both in-memory and on disk. The naive approach (i.e. the only one I'm capable of taking) might end up storing lots of separate lists or maps of data per user, which would soon unravel.
- Write amplification: every engagement by someone who
NThunderSky users will result inNwrites to each of their lists (assuming the naive approach outlined above).
Ranking improvements
For starters, the algorithm could do with a lot of refinement. The follower factor still doesn't handle whale accounts well enough, nor does it boost small ones. This is partially because I found doing so caused even more front page churn, which I found visually disorientating - but it definitely needs refinement. The time decay factor similarly needs work bearing in mind the more ephemeral nature of posts on Bluesky vs Hacker News, while still balancing in the churn factor.
Secondly, the shortcuts I've taken to keep memory pressure down mean that some posts might unfairly never end up being ranked. Some late night discourse with ChatGPT should help me be a better programmer and give more posts a chance here, which will be particularly important if personalisation becomes a reality (since the ranking cut-off point will have to be a lot lower).
User experience
I quite like the way the current website animates posts as they reorder themselves, and it helps the user understand what's happening. Thanks for that, Cursor. But there are doubtless a lot of improvements to be made here; user design and experience remains a weak point of mine despite the huge crutch of generative AI.
Wrapping up
gitinvoiced.com reckons I've spent about 12 hours hacking ThunderSky together, which is broadly accurate give or take some ChatGPT ideation and lots of furious note scribbling whenever ideas came to me. This number would be ten times that were it not for the enormous uplift from leaning so heavily on AI. As it stands today ThunderSky is just a bit of fun, and an excuse to dive into a fast-moving data set, but I'll do my best to keep it around while it's economically viable to do so. I promise I'll host the ranking process somewhere more suitable than my Mac really soon, and in the meantime if you'd like to see ThunderSky do something it currently doesn't, I suppose the best thing to do is to find me on Bluesky!